
集合的总结
小疑问
集合是干什么的,集合就是批量处理一些相同类型的数据,集合里装的都是引用类型的数据,如果要装入基本数据类型的东西,那么就把它们转换成包装类,八大基本数据类型都有所对应的包装类.
当时有这个疑惑,数组不是就是批量处理数据的,那么为什么还要引入集合那,数组中也可以放引用类型的数据啊.
下面和数组类比一下
- 声明数组时,必须要声明数组类型,java是强类型语言,集合在声明的时候不用声明具体的类型,集合中使用了泛型,修改方便,灵活.
- 声明数组时,必须要确定大小(二维数组至少要确定第一个下标的大小),但集合声明时,不用非要确定集合的大小,集合是可以动态扩展容量,可以根据需要动态改变大小,集合提供更多的成员方法,能满足更多的需求
- 数组是java语言中内置的数据类型,是基于硬件的,是线性排列的,执行效率或者类型检查,都是最快的.
ArrayList就是基于数组创建的容器类.所以说ArrayList的速度是集合中最快的(自己认为).
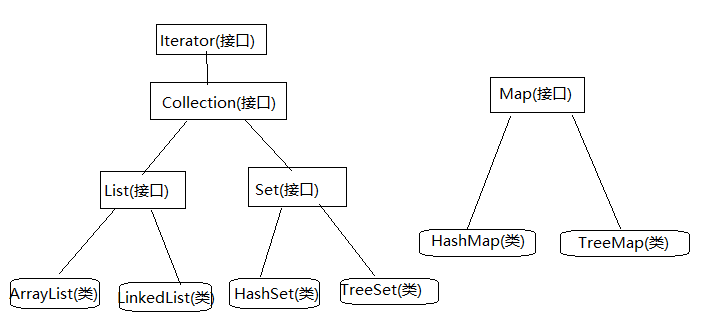
脑海中的集合体系
Collection接口继承自Iterator接口(迭代器),Collection接口下面包括两个接口,一个是List接口,另一个是Set接口,List(List下面会有他们的实现类)是可重复的,插入有序的;而Set(Set下面也会有实现类)是不可重复的,插入无序的(下面会讲到Set为什么是不可重复的).Map(Map目前不知道继承自哪里)接口下面有两个实现类,一个是HashMap,另一个是TreeMap.List接口下面有两个实现类(现在学的)一个是ArrayList,另一个是LinkedList.Set接口下面也有两个实现类(现在学的)一个是HashSet,另一个是TreeSet.Set集合就是Map的不完整版(自己理解的),Set只用了Map中的Key值,因为Map中Key不可以重复,所以理所应当`Set也就不可以重复了.
集合的分类
集合总的来说分为两大类,一类是Collection,一类是Map.Collection里存的就是引用数据类型(基本数据类型也可以往里存,把他装换成包装类);Map中存储的是键值对(键值对我自己理解为存的就是两个引用类型).1
2
3List<String> list = new ArrayList<String>();
Integer i= 1;//将基本数据类型int装入Integer中,这一步也叫自动装箱.
List<Integer> list = new ArrayList<Integer>();
泛型的介绍
在java的集合中引入了泛型,个人感觉就是因为他很灵活,在<>中可以填你任何想要的引用类型(基本数据类型可以通过装箱和拆箱来填入<>中),
Collection
ListSetList(ArrayList)
ArrayList的底层是数组,他是基于数组创建的容器类,ArrayList读取方便,但是插入不方便,他的排序是利用Collections的sort((List<T> list, Comparator<? super T> c))方法,List代表传入一个List对象,Comparator代表传入一个Comparator对象,这个Comparator对象可以是自己定义的MyComparator(必须实现Comparator接口)
因为ArrayList的底层是数组,所以他支持通过下标获得元素,也正是因为他的底层是数组,ArrayList中有很多对元素使用的方法,看JDK开发文档了解.ArrayList读取方便,因为他有下标我们可以通过获得他的下标来获取他空间里所存的东西,但是要想插入的话就很难了,因为ArrayList实际上是一个长度可以变的数组,插入入数据时,则需要先将原始数组中的数据复制到一个新的数组,随后再将数据赋值到新数组的指定位置;删除数据时,也是将原始数组中要保留的数据复制到一个新的数组,所以总结得知ArrayList读取查看方便,但是增添删除难.List(LinkedList)
LinkedList的底层是链表,LinkedList是一个由相互引用的节点组成的双向链表,那么当把数据插入至该链表某个位置时,该数据就会被组装成一个新的节点,随后只需改变链表中对应的两个节点之间的引用关系,使它们指向新节点,即可完成插入,意思就是把想要加的数据包装成一个节点,假如要在1和2之间插,那么包装的这个节点一个指向1,另一个指向2,就完成了添加,删除也是这个原理.LinkedList的排序也是利用Collections的sort()方法.sort()方法在Collections中有重载的,一个是两个参数的sort(List<T> list, Comparator<? super T> c),另一个是一个参数的sort(List<T> list),出现这两个方法的原因是Compareable接口和Comparator接口(下面会介绍).Set(hashSet)
HashSet的底层是HashMap,而HashMap的底层是数组与链表的结合,看到Hash这个单词我们就知道了这个类肯定和哈希值有关,我们知道Set其中的元素是不可重复的,无序的,这两个特性都和Hashcode()和equals()这两个方法有关,比较时先比较hashCode()如果hashCode()不等的话在比较equals()方法,java中自带的API都将hashCode()和equals()方法重写了,所以在Set中我们存入java中自带的API类型的对象的时候,都将去重,但是我们自己定义的类如果不去重写equals()和hashCode()方法,那么他将用的是Object中的这两个方法,自然就不会去重了,其实Set中的元素是有顺序的,但是这种顺序我们看不懂他是怎样排的,所以我们说他无序,这个排序和hashCode()也有关.Set(TreeSet)
TreeSet的底层是TreeMap,而TreeMap的底层是二叉树(二叉树其实也是链表,特殊的链表),TreeSet中确定元素的唯一性是通过Comparable接口中的 compareTo()方法,或者自定义比较器(Comparator)的Compare()方法来保证唯一性,实现这两个方法后可以按照我们想要的顺序进行排序,但是两个方法同时实现的话,Comparator会优先调用.通常我们也会重写equals和hashCode方法,来确保唯一性,保证不冲突.在获得对象的hashCode之后,会对他进行一个算法运算,这个运算完成后,就将他放到指定数组下标的链表中这时比对链表中有无相同的元素,有则替换掉,没有则加上,这也就是为什么要重写equals()的原因,当hashCode相同时,就要用到equals()了.- 通常用
HashSet来进行去重,然后用TreeSet来排序.
Map(HashMap)
HashMap的底层是数组与链表的结合,Map中有键(key)和值(value),就和地图上的坐标对应地点是一样的,可能有两个地方都叫”武安”,但是他们的地址或者说坐标绝对不同,因为地球上的点是唯一的,在Map中key就相当于坐标,只能有一个,不能重复;而vaule就相当于地名,可以重复.如果用HashMap类型对象进行排序的时候,记得把需要排序的对象放在Key的位置上,只有key的位置上才会进行排序.一般不用HashMap进行排序,主要用它进行去重. 自己定义的类一定要实现equals()和hashCode()方法,才会去重.Map(TreeMap)
TreeMap的底层是二叉树,通过确定元素的唯一性是通过Comparable接口中的compareTo()方法,或者自定义比较器(Comparator)的Compare()方法来保证唯一性,通常将HashMap()去重后的数据抛给TreeMap来排序.- 通常用
Comparator和Comparable
Comparator通过自定义
Comparator来排序,需要将里面的compare()方法重写.自定义的Comparator可以定义很多个,根据自己的需求.定义好了后将自己定义的MyComparator,传入定义的Map对象的()中就行,Map里有MyComparator为参数的构造方法.
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
import java.util.Comparator;
public class MyComparator implements Comparator<Student> {
public int compare(Student o1, Student o2) {
return o1.getShuxing-o2.getShuxing;
//如果是用的java中自带的API的话,比如String,String中已经将compareTO()重写直接用就行了.
//如果想有很多判断原则,比如第一原则,第二原则,会用到三目运算符.
}
}Comparable通过让自己定义的类来实现
Comparable接口来进行排序,实现了这个接口的话,就要实现接口中的CompareTo()方法,这个方法返回”0”就说明当前的元素和比较的元素是一样的,这是就不会返回元素,如果返回的是”1”或者”- 1”的时候就会返回一个元素,返回”1”,将这个元素放在当前元素的右边叉树,返回”- 1”放在当前元素的左边.方法体的实现和compare()的套路是一样的.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Student implements Comparable<Student> {
private String name;//name属性
//Getter和Setter方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//重写toString,一般自定义类都要重写
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
public int compareTo(Student o) {
//会通过一个字典来进行比较
return this.name.compareTO(o.getName())
一个类通常也会重写这两个方法,但我们这里重写就不实现了
public int hashCode(){}
public boolean equals(Object obj){}
}
疑问
TreeSet是用ComparaTo()或者compara()方法来保证唯一性的,为什么还要在自定义类中重写equals()和hashCode()方法那.
通过查API文档,原因是这样的:因为 Set 接口是按照 equals 操作定义的,
但 TreeSet 实例使用它的 compareTo(或 compare)方法对所有元素进行比较,因此从 set 的观点来看,
此方法认为相等的两个元素就是相等的,为保证equals方法定义相等的比较方式和指定比较器定义相等的方式相符合,
就把它们都写上了,这样就不会不一致,而当equals方法被重写时,通常有必要重写hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码.

